Introduction à pandas
Pour visualiser le TP associé à ce tutoriel :
Dans ce tutoriel pandas, nous allons utiliser:
- Les émissions de gaz à effet de serre estimées au niveau communal par l’ADEME. Le jeu de données est disponible sur data.gouv et requêtable directement dans python avec cet url
- Quelques données de contexte au niveau communal. Idéalement, on utiliserait les données disponibles sur le site de l’Insee. Pour faciliter l’import de celles-ci, les données ont été mises à disposition dans le dépôt github, sur cet url
⚠ pandas offre la possibilité d’importer des données
directement depuis un url. C’est l’option prise dans ce tutoriel.
Si vous préfèrez, pour des
raisons d’accès au réseau ou de performance, importer depuis un poste local,
vous pouvez télécharger les données et changer
les commandes d’import avec le chemin adéquat plutôt que l’url.
Nous suivrons les conventions habituelles dans l’import des packages
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
Pour obtenir des résultats reproductibles, on peut fixer la racine du générateur pseudo-aléatoire.
np.random.seed(123)
Au cours de cette démonstration des principales fonctionalités de pandas, et
lors du TP
![]()
![]()
, je recommande de régulièrement se référer aux ressources suivantes:
- L’aide officielle de pandas. Notamment, la page de comparaison des langages est très utile
- La cheatsheet suivante, issue de ce post

Logique de pandas
L’objet central dans la logique pandas est le DataFrame.
Il s’agit d’une structure particulière de données
à deux dimensions, structurées en alignant des lignes et colonnes. Les colonnes
peuvent être de type différent.
Un DataFrame est composé des éléments suivants:
- l’indice de la ligne ;
- le nom de la colonne ;
- la valeur de la donnée ;
Structuration d’un DataFrame pandas, emprunté à https://medium.com/epfl-extension-school/selecting-data-from-a-pandas-dataframe-53917dc39953:

Le concept de tidy data, popularisé par Hadley Wickham via ses packages R,
est parfaitement pertinent pour décrire la structure d’un DataFrame pandas.
Les trois règles sont les suivantes:
- Chaque variable possède sa propre colonne
- Chaque observation possède sa propre ligne
- Une valeur, matérialisant la valeur d’une observation d’une variable, se trouve sur une unique cellule.

⚠ Les DataFrames sont assez rapides en Python1 et permettent de traiter de manière efficace des tables de
données comportant plusieurs millions d’observations et dont la volumétrie peut être conséquente (plusieurs centaines
de Mo). Néanmoins, passé un certain seuil, qui dépend de la puissance de la machine mais aussi de la complexité
de l’opération effectuée, le DataFrame pandas peut montrer certaines limites. Dans ce cas, il existe différentes
solutions: dask (dataframe aux opérations parallélisés), SQL (notamment posgres), spark (solution big data)
Concernant la syntaxe, une partie des commandes python est inspirée par la logique SQL. On retrouvera ainsi des instructions relativement transparentes.
Il est vivement recommandé, avant de se lancer dans l'écriture d’une
fonction, de se poser la question de son implémentation native dans numpy, pandas, etc.
En particulier, la plupart du temps, les boucles sont à bannir.
Les Series
En fait, un DataFrame est une collection d’objets appelés pandas.Series.
Ces Series sont des objets d’une dimension qui sont des extensions des
array-unidimensionnels numpy. En particulier, pour faciliter le traitement
de données catégorielles ou temporelles, des types de variables
supplémentaires sont disponibles dans pandas par rapport à
numpy (categorical, datetime64 et timedelta64). Ces
types sont associés à des méthodes optimisées pour faciliter le traitement
de ces données.
Il ne faut pas négliger l’attribut dtype d’un objet
pandas.Series car cela a une influence déterminante sur les méthodes
et fonctions pouvant être utilisés (on ne fait pas les mêmes opérations
sur une donnée temporelle et une donnée catégorielle) et le volume en
mémoire d’une variable (le type de la variable détermine le volume
d’information stocké pour chaque élément ; être trop précis est parfois
néfaste).
Indexation
La différence essentielle entre une Series et un objet numpy est l’indexation.
Dans numpy,
l’indexation est implicite ; elle permet d’accéder à une donnée (celle à
l’index situé à la position i).
Avec une Series, on peut bien-sûr utiliser un indice de position mais on peut
surtout faire appel à des indices plus explicites.
Par exemple,
taille = pd.Series(
[1.,1.5,1],
index = ['chat', 'chien', 'koala']
)
taille.head()
## chat 1.0
## chien 1.5
## koala 1.0
## dtype: float64
Cette indexation permet d’accéder à des valeurs de la Series
via une valeur de l’indice. Par
exemple, taille['koala']:
taille['koala']
## 1.0
L’existence d’indice rend le subsetting particulièrement aisé, ce que vous
pouvez expérimenter dans les TP
![]()
![]() (ou depuis github)
(ou depuis github)
Pour transformer un objet pandas.Series en array numpy,
on utilise la méthode values. Par exemple, taille.values:
taille.values
## array([1. , 1.5, 1. ])
Un avantage des Series par rapport à un array numpy est que
les opérations sur les Series alignent
automatiquement les données à partir des labels.
Avec des Series labélisées, il n’est ainsi pas nécessaire
de se poser la question de l’ordre des lignes.
L’exemple dans la partie suivante permettra de s’en assurer.
Valeurs manquantes
Par défaut, les valeurs manquantes sont affichées NaN et sont de type np.nan (pour
les valeurs temporelles, i.e. de type datatime64, les valeurs manquantes sont
NaT).
On a un comportement cohérent d’agrégation lorsqu’on combine deux DataFrames (ou deux colonnes).
Par exemple,
x = pd.DataFrame(
{'prix': np.random.uniform(size = 5),
'quantite': [i+1 for i in range(5)]
},
index = ['yaourt','pates','riz','tomates','gateaux']
)
y = pd.DataFrame(
{'prix': [np.nan, 0, 1, 2, 3],
'quantite': [i+1 for i in range(5)]
},
index = ['tomates','yaourt','gateaux','pates','riz']
)
x + y
## prix quantite
## gateaux 1.719469 8
## pates 2.286139 6
## riz 3.226851 8
## tomates NaN 5
## yaourt 0.696469 3
donne bien une valeur manquante pour la ligne tomates. Au passage, on peut remarquer que l’agrégation
a tenu compte des index.
Le DataFrame pandas
Le DataFrame est l’objet central du package pandas.
Il s’agit d’une collection de pandas.Series (colonnes) alignées par les lignes.
Les types des variables peuvent différer.
Un DataFrame non-indexé a la structure suivante:
## index taille poids
## 0 chat 1.0 3.0
## 1 chien 1.5 5.0
## 2 koala 1.0 2.5
Alors que le même dataframe indexé aura la structure suivante:
## taille poids
## chat 1.0 3.0
## chien 1.5 5.0
## koala 1.0 2.5
Les attributs et méthodes utiles
Pour présenter les méthodes les plus pratiques pour l’analyse de données,
on peut partir de l’exemple des consommations de CO2 communales issues
des données de l’Ademe. Cette base de données est exploitée plus intensément
dans le TP
![]()
![]() (ou depuis github)
(ou depuis github)
df = pd.read_csv("https://koumoul.com/s/data-fair/api/v1/datasets/igt-pouvoir-de-rechauffement-global/convert")
df
## INSEE commune Commune ... Routier Tertiaire
## 0 01001 L'ABERGEMENT-CLEMENCIAT ... 793.156501 367.036172
## 1 01002 L'ABERGEMENT-DE-VAREY ... 348.997893 112.934207
## 2 01004 AMBERIEU-EN-BUGEY ... 15642.420310 10732.376930
## 3 01005 AMBERIEUX-EN-DOMBES ... 1756.341319 782.404357
## 4 01006 AMBLEON ... 398.786800 51.681756
## ... ... ... ... ... ...
## 35793 95676 VILLERS-EN-ARTHIES ... 309.627908 235.439109
## 35794 95678 VILLIERS-ADAM ... 18759.370070 403.404815
## 35795 95680 VILLIERS-LE-BEL ... 12217.122400 13849.512000
## 35796 95682 VILLIERS-LE-SEC ... 4663.232127 85.657725
## 35797 95690 WY-DIT-JOLI-VILLAGE ... 504.400972 147.867245
##
## [35798 rows x 12 columns]
L’affichage des DataFrames est très ergonomique. On obtiendrait le même output
avec display(df)[^2]. Les premières et dernières lignes s’affichent
automatiquement. Autrement, on peut aussi faire:
headqui permet, comme son nom l’indique, de n’afficher que les premières lignes ;tailqui permet, comme son nom l’indique, de n’afficher que les dernières lignessamplequi permet d’afficher un échantillon aléatoire de n lignes. Cette méthode propose de nombreuses options
 (ou depuis github)
(ou depuis github)
^[2]: Il est préférable d’utiliser la fonction display (ou tout simplement
taper le nom du DataFrame qu’utiliser la fonction print). Le
display des objets pandas est assez esthétique, contrairement à print
qui renvoie du texte brut.
warning
Dimensions et structure du DataFrame
Les premières méthodes utiles permettent d’afficher quelques attributs d’un DataFrame.
df.axes
## [RangeIndex(start=0, stop=35798, step=1), Index(['INSEE commune', 'Commune', 'Agriculture', 'Autres transports',
## 'Autres transports international', 'CO2 biomasse hors-total', 'Déchets',
## 'Energie', 'Industrie hors-énergie', 'Résidentiel', 'Routier',
## 'Tertiaire'],
## dtype='object')]
df.columns
## Index(['INSEE commune', 'Commune', 'Agriculture', 'Autres transports',
## 'Autres transports international', 'CO2 biomasse hors-total', 'Déchets',
## 'Energie', 'Industrie hors-énergie', 'Résidentiel', 'Routier',
## 'Tertiaire'],
## dtype='object')
df.index
## RangeIndex(start=0, stop=35798, step=1)
Pour connaître les dimensions d’un DataFrame, on peut utiliser quelques méthodes pratiques:
df.ndim
## 2
df.shape
## (35798, 12)
df.size
## 429576
Pour déterminer le nombre de valeurs uniques d’une variable, plutôt que chercher à écrire soi-même une fonction,
on utilise la
méthode nunique. Par exemple,
df['Commune'].nunique()
## 33338
Voici un premier résumé des méthodes pandas utiles, et un comparatif avec R
| Opération | pandas | dplyr (R) |
data.table (R) |
|---|---|---|---|
| Récupérer le nom des colonnes | df.columns |
colnames(df) |
colnames(df) |
| Récupérer les indices[^3] | df.index |
unique(df[,get(key(df))]) |
|
| Récupérer les dimensions | df.shape |
c(nrow(df), ncol(df)) |
c(nrow(df), ncol(df)) |
| Récupérer le nombre de valeurs uniques d’une variable | df['myvar'].nunique() |
df %>% summarise(distinct(myvar)) |
df[,uniqueN(myvar)] |
^[3]: Le principe d’indice n’existe pas dans dplyr. Les indices, au sens de
pandas, sont appelés clés en data.table.
Statistiques agrégées
pandas propose une série de méthodes pour faire des statistiques
agrégées de manière efficace.
On peut, par exemple, appliquer des méthodes pour compter le nombre de lignes, faire une moyenne ou une somme de l’ensemble des lignes
df.count()
## INSEE commune 35798
## Commune 35798
## Agriculture 35736
## Autres transports 9979
## Autres transports international 2891
## CO2 biomasse hors-total 35798
## Déchets 35792
## Energie 34490
## Industrie hors-énergie 34490
## Résidentiel 35792
## Routier 35778
## Tertiaire 35798
## dtype: int64
df.mean()
## Agriculture 2459.975760
## Autres transports 654.919940
## Autres transports international 7692.344960
## CO2 biomasse hors-total 1774.381550
## Déchets 410.806329
## Energie 662.569846
## Industrie hors-énergie 2423.127789
## Résidentiel 1783.677872
## Routier 3535.501245
## Tertiaire 1105.165915
## dtype: float64
df.sum()
## INSEE commune 0100101002010040100501006010070100801009010100...
## Commune L'ABERGEMENT-CLEMENCIATL'ABERGEMENT-DE-VAREYAM...
## Agriculture 8.79097e+07
## Autres transports 6.53545e+06
## Autres transports international 2.22386e+07
## CO2 biomasse hors-total 6.35193e+07
## Déchets 1.47036e+07
## Energie 2.2852e+07
## Industrie hors-énergie 8.35737e+07
## Résidentiel 6.38414e+07
## Routier 1.26493e+08
## Tertiaire 3.95627e+07
## dtype: object
df.nunique()
## INSEE commune 35798
## Commune 33338
## Agriculture 35576
## Autres transports 9963
## Autres transports international 2883
## CO2 biomasse hors-total 35798
## Déchets 11016
## Energie 1453
## Industrie hors-énergie 1889
## Résidentiel 35791
## Routier 35749
## Tertiaire 8663
## dtype: int64
df.quantile(q = [0.1,0.25,0.5,0.75,0.9])
## Agriculture Autres transports ... Routier Tertiaire
## 0.10 382.620882 25.034578 ... 199.765410 49.289082
## 0.25 797.682631 52.560412 ... 419.700460 94.749885
## 0.50 1559.381286 106.795928 ... 1070.895593 216.297718
## 0.75 3007.883903 237.341501 ... 3098.612157 576.155869
## 0.90 5442.727470 528.349529 ... 8151.047248 1897.732565
##
## [5 rows x 10 columns]
Les exercices de TD (![]()
![]() ou depuis github)
visent à démontrer l’intérêt de ces méthodes dans quelques cas précis.
ou depuis github)
visent à démontrer l’intérêt de ces méthodes dans quelques cas précis.
Le tableau suivant récapitule le code équivalent pour avoir des
statistiques sur toutes les colonnes d’un dataframe en R.
| Opération | pandas | dplyr (R) |
data.table (R) |
|
|---|---|---|---|---|
| Nombre de valeurs non manquantes | df.count() |
df %>% summarise_each(funs(sum(!is.na(.)))) |
df[, lapply(.SD, function(x) sum(!is.na(x)))] |
|
| Moyenne de toutes les variables | df.mean() |
df %>% summarise_each(funs(mean((., na.rm = TRUE)))) |
df[,lapply(.SD, function(x) mean(x, na.rm = TRUE))] |
|
| TO BE CONTINUED |
La méthode describe permet de sortir un tableau de statistiques
agrégées:
df.describe()
## Agriculture Autres transports ... Routier Tertiaire
## count 35736.000000 9979.000000 ... 35778.000000 35798.000000
## mean 2459.975760 654.919940 ... 3535.501245 1105.165915
## std 2926.957701 9232.816833 ... 9663.156628 5164.182507
## min 0.003432 0.000204 ... 0.555092 0.000000
## 25% 797.682631 52.560412 ... 419.700460 94.749885
## 50% 1559.381286 106.795928 ... 1070.895593 216.297718
## 75% 3007.883903 237.341501 ... 3098.612157 576.155869
## max 98949.317760 513140.971700 ... 586054.672800 288175.400100
##
## [8 rows x 10 columns]
Méthodes relatives aux valeurs manquantes
Les méthodes relatives aux valeurs manquantes peuvent être mobilisées
en conjonction des méthodes de statistiques agrégées. C’est utiles lorsqu’on
désire obtenir une idée de la part de valeurs manquantes dans un jeu de
données
![]()
![]() (ou depuis github)
(ou depuis github)
df.isnull().sum()
Graphiques rapides
Les méthodes par défaut de graphique (approfondies dans la partie visualisation LIEN A AJOUTER) sont pratiques pour produire rapidement un graphique, notament après des opérations complexes de maniement de données.
fig = df['Déchets'].plot()
plt.show()

fig = df['Déchets'].hist()
plt.show()

fig = df['Déchets'].plot(kind = 'hist', logy = True)
plt.show()

La sortie est un objet matplotlib. La customisation de ces
figures est ainsi
possible (et même désirable car les graphiques matplotlib
sont, par défaut, assez rudimentaires), nous en verrons quelques exemples.
Accéder à des éléments d’un DataFrame
Sélectionner des colonnes
En SQL, effectuer des opérations sur les colonnes se fait avec la commande
SELECT. Avec pandas,
pour accéder à une colonne dans son ensemble on peut
utiliser plusieurs approches:
dataframe.variable, par exempledf.Energie. Cette méthode requiert néanmoins d’avoir des noms de colonnes sans espace.dataframe[['variable']]pour renvoyer la variable sous forme deDataFrameou dataframe[‘variable’] pour la renvoyer sous forme deSeries. Par exemple,df[['Autres transports']]oudf['Autres transports']. C’est une manière préférable de procéder.
Accéder à des lignes
Pour accéder à une ou plusieurs valeurs d’un DataFrame,
il existe trois manières de procéder, selon la
forme des indices de lignes ou colonnes utilisés:
df.loc: use labelsdf.iloc: use indicesdf[]: uses
Les bouts de code utilisant la structure df.ix
sont à bannir car la fonction est deprecated et peut
ainsi disparaître à tout moment.
EXEMPLES A DONNER
Principales manipulation de données
L’objectif du TP pandas est de se familiariser plus avec ces commandes à travers l’exemple des données des émissions de C02.
Les opérations les plus fréquentes en SQL sont résumées par le tableau suivant. Il est utile de les connaître (beaucoup de syntaxes de maniement de données reprennent ces termes) car, d’une manière ou d’une autre, elles couvrent la plupart des usages de manipulation des données
| Opération | SQL | pandas | dplyr (R) |
data.table (R) |
|---|---|---|---|---|
| Sélectionner des variables par leur nom | SELECT |
df[['Autres transports','Energie']] |
df %>% select(Autres transports, Energie) |
df[, c('Autres transports','Energie')] |
| Sélectionner des observations selon une ou plusieurs conditions; | FILTER |
df[df['Agriculture']>2000] |
df %>% filter(Agriculture>2000) |
df[Agriculture>2000] |
| Trier la table selon une ou plusieurs variables | SORT BY |
df.sort_values(['Commune','Agriculture']) |
df %>% arrange(Commune, Agriculture) |
df[order(Commune, Agriculture)] |
| Ajouter des variables qui sont fonction d’autres variables; | SELECT *, LOG(Agriculture) AS x FROM df |
df['x'] = np.log(df['Agriculture']) |
df %>% mutate(x = log(Agriculture)) |
df[,x := log(Agriculture)] |
| Effectuer une opération par groupe | GROUP BY |
df.groupby('Commune').mean() |
df %>% group_by(Commune) %>% summarise(m = mean) |
df[,mean(Commune), by = Commune] |
| Joindre deux bases de données (inner join) | SELECT * FROM table1 INNER JOIN table2 ON table1.id = table2.x |
table1.merge(table2, left_on = 'id', right_on = 'x') |
table1 %>% inner_join(table2, by = c('id'='x')) |
merge(table1, table2, by.x = 'id', by.y = 'x') |
Opérations sur les colonnes: select, mutate, drop
Les DataFrames pandas sont des objets mutables en langage python,
c’est-à-dire qu’il est possible de faire évoluer le DataFrame au grès
des opérations. L’opération la plus classique consiste à ajouter ou retirer
des variables à la table de données.
warning
La manière la plus simple d’opérer pour ajouter des colonnes est
d’utiliser la réassignation. Par exemple, pour créer une variable
x qui est le log de la
variable Agriculture:
df_new['x'] = np.log(df_new['Agriculture'])
Il est possible d’appliquer cette approche sur plusieurs colonnes. Un des intérêts de cette approche est qu’elle permet de recycler le nom de colonnes.
vars = ['Agriculture', 'Déchets', 'Energie']
df_new[[v + "_log" for v in vars]] = np.log(df_new[vars])
df_new
## INSEE commune Commune ... Déchets_log Energie_log
## 0 01001 L'ABERGEMENT-CLEMENCIAT ... 4.619374 0.856353
## 1 01002 L'ABERGEMENT-DE-VAREY ... 4.946455 0.856353
## 2 01004 AMBERIEU-EN-BUGEY ... 8.578159 6.906086
## 3 01005 AMBERIEUX-EN-DOMBES ... 5.376285 4.545232
## 4 01006 AMBLEON ... 3.879532 NaN
## ... ... ... ... ... ...
## 35793 95676 VILLERS-EN-ARTHIES ... 4.175366 2.465791
## 35794 95678 VILLIERS-ADAM ... 4.713854 0.856353
## 35795 95680 VILLIERS-LE-BEL ... 5.418865 6.281303
## 35796 95682 VILLIERS-LE-SEC ... 4.691070 0.856353
## 35797 95690 WY-DIT-JOLI-VILLAGE ... 4.582194 1.549500
##
## [35798 rows x 16 columns]
Il est également possible d’utiliser la méthode assign. Pour des opérations
vectorisées, comme le sont les opérateurs de numpy, cela n’a pas d’intérêt.
Mais dans certains cas, où on serait tenté (à tord !), d’utiliser une boucle,
alors cette approche peut se justifier. Cette approche utilise généralement
des lambda functions. Par exemple le code précédent prendrait la forme:
df_new.assign(Energie_log = lambda x: np.log(x['Energie']))
## INSEE commune Commune ... Déchets_log Energie_log
## 0 01001 L'ABERGEMENT-CLEMENCIAT ... 4.619374 0.856353
## 1 01002 L'ABERGEMENT-DE-VAREY ... 4.946455 0.856353
## 2 01004 AMBERIEU-EN-BUGEY ... 8.578159 6.906086
## 3 01005 AMBERIEUX-EN-DOMBES ... 5.376285 4.545232
## 4 01006 AMBLEON ... 3.879532 NaN
## ... ... ... ... ... ...
## 35793 95676 VILLERS-EN-ARTHIES ... 4.175366 2.465791
## 35794 95678 VILLIERS-ADAM ... 4.713854 0.856353
## 35795 95680 VILLIERS-LE-BEL ... 5.418865 6.281303
## 35796 95682 VILLIERS-LE-SEC ... 4.691070 0.856353
## 35797 95690 WY-DIT-JOLI-VILLAGE ... 4.582194 1.549500
##
## [35798 rows x 16 columns]
On peut facilement renommer des variables avec la méthode rename qui
fonctionne bien avec des dictionnaires :
df_new.rename({"Energie": "eneg", "Agriculture": "agr"})
## INSEE commune Commune ... Déchets_log Energie_log
## 0 01001 L'ABERGEMENT-CLEMENCIAT ... 4.619374 0.856353
## 1 01002 L'ABERGEMENT-DE-VAREY ... 4.946455 0.856353
## 2 01004 AMBERIEU-EN-BUGEY ... 8.578159 6.906086
## 3 01005 AMBERIEUX-EN-DOMBES ... 5.376285 4.545232
## 4 01006 AMBLEON ... 3.879532 NaN
## ... ... ... ... ... ...
## 35793 95676 VILLERS-EN-ARTHIES ... 4.175366 2.465791
## 35794 95678 VILLIERS-ADAM ... 4.713854 0.856353
## 35795 95680 VILLIERS-LE-BEL ... 5.418865 6.281303
## 35796 95682 VILLIERS-LE-SEC ... 4.691070 0.856353
## 35797 95690 WY-DIT-JOLI-VILLAGE ... 4.582194 1.549500
##
## [35798 rows x 16 columns]
Enfin, pour effacer des colonnes, on utilise la méthode drop avec l’argument
columns:
df_new.drop(columns = ["Energie", "Agriculture"])
## INSEE commune Commune ... Déchets_log Energie_log
## 0 01001 L'ABERGEMENT-CLEMENCIAT ... 4.619374 0.856353
## 1 01002 L'ABERGEMENT-DE-VAREY ... 4.946455 0.856353
## 2 01004 AMBERIEU-EN-BUGEY ... 8.578159 6.906086
## 3 01005 AMBERIEUX-EN-DOMBES ... 5.376285 4.545232
## 4 01006 AMBLEON ... 3.879532 NaN
## ... ... ... ... ... ...
## 35793 95676 VILLERS-EN-ARTHIES ... 4.175366 2.465791
## 35794 95678 VILLIERS-ADAM ... 4.713854 0.856353
## 35795 95680 VILLIERS-LE-BEL ... 5.418865 6.281303
## 35796 95682 VILLIERS-LE-SEC ... 4.691070 0.856353
## 35797 95690 WY-DIT-JOLI-VILLAGE ... 4.582194 1.549500
##
## [35798 rows x 14 columns]
Reordonner
La méthode sort_values permet de réordonner un DataFrame. Par exemple,
si on désire classer par ordre décroissant de consommation de CO2 du secteur
résidentiel, on fera
df.sort_values("Résidentiel", ascending = False)
## INSEE commune Commune ... Routier Tertiaire
## 12167 31555 TOULOUSE ... 586054.672800 288175.4001
## 16774 44109 NANTES ... 221068.632700 173447.5828
## 27294 67482 STRASBOURG ... 279544.852300 179562.7614
## 12729 33063 BORDEAUX ... 193411.085700 142475.5641
## 22834 59350 LILLE ... 265561.183600 175581.6190
## ... ... ... ... ... ...
## 20742 55050 BEZONVAUX ... 113.221722 0.0000
## 20817 55139 CUMIERES-LE-MORT-HOMME ... 128.733542 0.0000
## 20861 55189 FLEURY-DEVANT-DOUAUMONT ... 1435.571489 0.0000
## 20898 55239 HAUMONT-PRES-SAMOGNEUX ... 91.920170 0.0000
## 20957 55307 LOUVEMONT-COTE-DU-POIVRE ... 236.928053 0.0000
##
## [35798 rows x 12 columns]
Ainsi, en une ligne de code, on identifie les villes où le secteur résidentiel consomme le plus.
Filtrer
L’opération de sélection de lignes s’appelle FILTER en SQL et s’utilise
en fonction d’une condition logique (clause WHERE). On sélectionne les
données sur une condition logique. Il existe plusieurs méthodes en pandas.
La plus simple est d’utiliser les boolean mask, déjà vus dans le chapitre
numpy [LIEN].
Par exemple, pour sélectionner les communes dans les Hauts-de-Seine, on
peut utiliser le résultat de la méthode str.startswith (qui renvoie
True ou False) directement dans les crochets:
df[df['INSEE commune'].str.startswith("92")].head(2)
## INSEE commune Commune ... Routier Tertiaire
## 35490 92002 ANTONY ... 58900.97969 31462.0380
## 35491 92004 ASNIERES-SUR-SEINE ... 38163.01602 42482.6351
##
## [2 rows x 12 columns]
Pour remplacer des valeurs spécifiques, on utilise la méthode where ou une
réassignation couplée à la méthode précédente.
Par exemple, pour assigner des valeurs manquantes aux départements du 92, on peut faire cela
df_copy = df.copy()
df_copy = df_copy.where(~df['INSEE commune'].str.startswith("92"))
et vérifier les résultats:
df_copy[df['INSEE commune'].str.startswith("92")].head(2)
## INSEE commune Commune Agriculture ... Résidentiel Routier Tertiaire
## 35490 NaN NaN NaN ... NaN NaN NaN
## 35491 NaN NaN NaN ... NaN NaN NaN
##
## [2 rows x 12 columns]
df_copy[~df['INSEE commune'].str.startswith("92")].head(2)
## INSEE commune Commune ... Routier Tertiaire
## 0 01001 L'ABERGEMENT-CLEMENCIAT ... 793.156501 367.036172
## 1 01002 L'ABERGEMENT-DE-VAREY ... 348.997893 112.934207
##
## [2 rows x 12 columns]
ou alors utiliser une réassignation plus classique:
df_copy = df.copy()
df_copy[df_copy['INSEE commune'].str.startswith("92")] = np.nan
Opérations par groupe
En SQL, il est très simple de découper des données pour
effectuer des opérations sur des blocs cohérents et recollecter des résultats
dans la dimension appropriée.
La logique sous-jacente est celle du split-apply-combine qui est repris
par les langages de manipulation de données, auxquels pandas
ne fait pas exception.
L’image suivante, issue de
ce site
représente bien la manière dont fonctionne l’approche
split-apply-combine
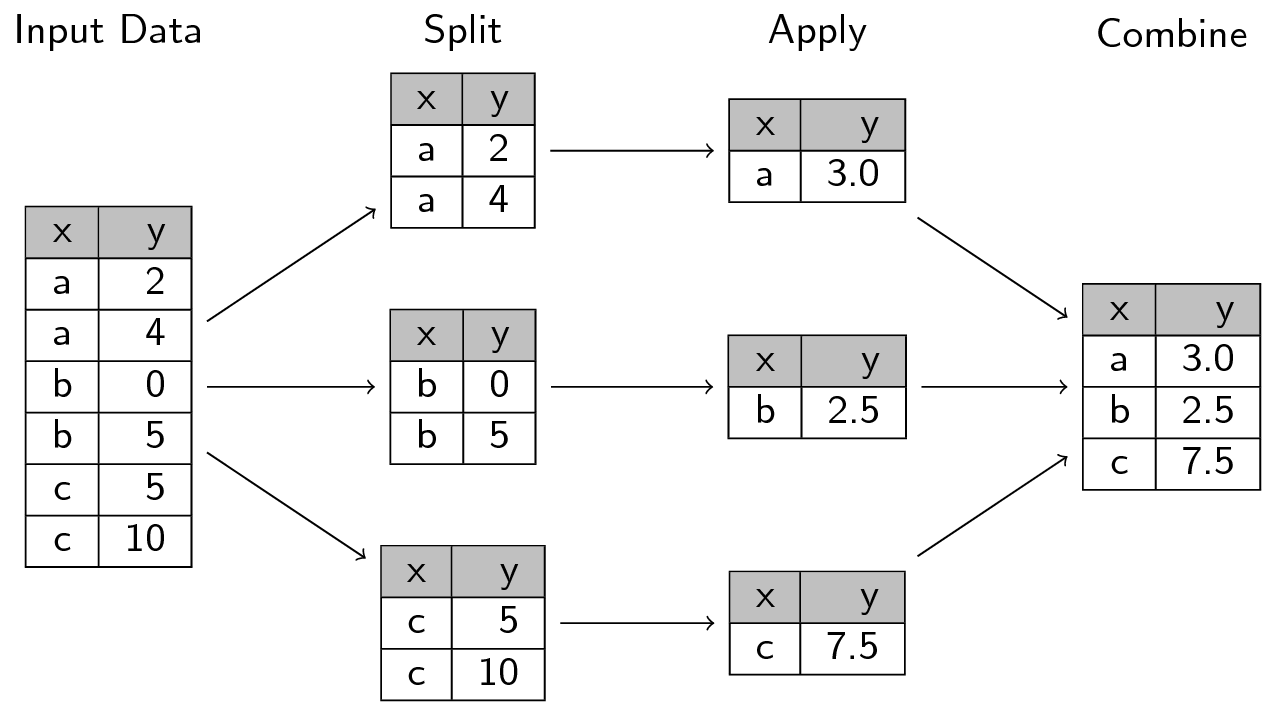
Ce tutoriel sur le sujet est particulièrement utile.
Pour donner quelques exemples, on peut créer une variable départementale qui servira de critère de groupe.
df['dep'] = df['INSEE commune'].str[:2]
En pandas, on utilise groupby pour découper les données selon un ou
plusieurs axes. Techniquement, cette opération consiste à créer une association
entre des labels (valeurs des variables de groupe) et des
observations.
Par exemple, pour compter le nombre de communes par département en SQL, on utiliserait la requête suivante:
SELECT dep, count(INSEE commune)
FROM df
GROUP BY dep;
Ce qui, en pandas, donne:
df.groupby('dep')["INSEE commune"].count()
## dep
## 01 410
## 02 805
## 03 318
## 04 199
## 05 168
## ...
## 91 196
## 92 36
## 93 40
## 94 47
## 95 185
## Name: INSEE commune, Length: 96, dtype: int64
La syntaxe est quasiment transparente. On peut bien-sûr effecter des opérations par groupe sur plusieurs colonnes. Par exemple,
df.groupby('dep').mean
## <bound method GroupBy.mean of <pandas.core.groupby.generic.DataFrameGroupBy object at 0x0000000036774438>>
A noter que la variable de groupe, ici dep, devient, par défaut, l’index
du DataFrame de sortie. Si on avait utilisé plusieurs variables de groupe,
on obtiendrait un objet multi-indexé.
Tant qu’on appelle pas une action sur un DataFrame par groupe, du type
head ou display, pandas n’effectue aucune opération. On parle de
lazy evaluation. Par exemple, le résultat de df.groupby('dep') est
une transformation qui n’est pas encore évaluée:
df.groupby('dep')
## <pandas.core.groupby.generic.DataFrameGroupBy object at 0x0000000036774748>
Il est possible d’appliquer plus d’une opération à la fois grâce à la méthode
agg. Par exemple, pour obtenir à la fois le minimum, la médiane et le maximum
de chaque département, on peut faire:
df.groupby('dep').agg(['min',"median","max"])
## Agriculture ... Tertiaire
## min median ... median max
## dep ...
## 01 0.003432 1304.519570 ... 401.490676 30847.36686
## 02 0.391926 1205.725078 ... 130.639994 34159.34575
## 03 5.041238 5382.194339 ... 191.892445 31099.77288
## 04 30.985972 1404.752852 ... 122.504902 16478.02481
## 05 38.651727 1520.896526 ... 151.695524 23666.23590
## .. ... ... ... ... ...
## 91 0.400740 516.908303 ... 1428.426303 38296.20473
## 92 0.073468 6.505185 ... 18086.633085 65043.36450
## 93 3.308495 3.308495 ... 20864.923340 71918.16398
## 94 1.781885 1.781885 ... 14054.223450 58528.62348
## 95 8.779506 445.279844 ... 725.467969 61497.82148
##
## [96 rows x 30 columns]
Appliquer des fonctions
pandas est, comme on a pu le voir, un package très flexible, qui
propose une grande variété de méthodes optimisées. Cependant, il est fréquent
d’avoir besoin de méthodes non implémentées.
Dans ce cas, on recourt souvent aux lambda functions. Par exemple, si
on désire connaître les communes dont le nom fait plus de 10 caractères,
on peut appliquer la fonction len de manière itérative:
df[df['Commune'].apply(lambda s: len(s)>10)]
## INSEE commune Commune ... Tertiaire dep
## 0 01001 L'ABERGEMENT-CLEMENCIAT ... 367.036172 01
## 1 01002 L'ABERGEMENT-DE-VAREY ... 112.934207 01
## 2 01004 AMBERIEU-EN-BUGEY ... 10732.376930 01
## 3 01005 AMBERIEUX-EN-DOMBES ... 782.404357 01
## 7 01009 ANDERT-ET-CONDON ... 161.266219 01
## ... ... ... ... ... ...
## 35793 95676 VILLERS-EN-ARTHIES ... 235.439109 95
## 35794 95678 VILLIERS-ADAM ... 403.404815 95
## 35795 95680 VILLIERS-LE-BEL ... 13849.512000 95
## 35796 95682 VILLIERS-LE-SEC ... 85.657725 95
## 35797 95690 WY-DIT-JOLI-VILLAGE ... 147.867245 95
##
## [16289 rows x 13 columns]
Cependant, toutes les lambda functions ne se justifient pas.
Par exemple, prenons
le résultat d’agrégation précédent. Imaginons qu’on désire avoir les résultats
en milliers de tonnes. Dans ce cas, le premier réflexe est d’utiliser
la lambda function suivante:
df.groupby('dep').agg(['min',"median","max"])
## Agriculture ... Tertiaire
## min median ... median max
## dep ...
## 01 0.003432 1304.519570 ... 401.490676 30847.36686
## 02 0.391926 1205.725078 ... 130.639994 34159.34575
## 03 5.041238 5382.194339 ... 191.892445 31099.77288
## 04 30.985972 1404.752852 ... 122.504902 16478.02481
## 05 38.651727 1520.896526 ... 151.695524 23666.23590
## .. ... ... ... ... ...
## 91 0.400740 516.908303 ... 1428.426303 38296.20473
## 92 0.073468 6.505185 ... 18086.633085 65043.36450
## 93 3.308495 3.308495 ... 20864.923340 71918.16398
## 94 1.781885 1.781885 ... 14054.223450 58528.62348
## 95 8.779506 445.279844 ... 725.467969 61497.82148
##
## [96 rows x 30 columns]
En effet, cela effectue le résultat désiré. Cependant, il y a mieux: utiliser
la méthode div:
import timeit
%timeit df.groupby('dep').agg(['min',"median","max"]).div(1000)
%timeit df.groupby('dep').agg(['min',"median","max"]).apply(lambda s: s/1000)
La méthode div est en moyenne plus rapide et a un temps d’exécution
moins variable. Dans ce cas, on pourrait même utiliser le principe
du broadcasting de numpy (cf. chapitre numpy) qui offre
des performances équivalentes:
%timeit df.groupby('dep').agg(['min',"median","max"])/1000
apply est plus rapide qu’une boucle (en interne, apply utilise Cython
pour itérer) mais reste moins rapide qu’une solution vectorisée quand
elle existe. Ce site
propose des solutions, par exemple les méthodes isin ou digitize, pour
éviter de manuellement créer des boucles lentes.
Joindre
L’information de valeur s’obtient de moins en moins à partir d’une unique base de données. Il devient commun de devoir combiner des données issues de sources différentes. Nous allons ici nous focaliser sur le cas le plus favorable qui est la situation où une information permet d’apparier de manière exacte deux bases de données (autrement nous serions dans une situation, beaucoup plus complexe, d’appariement flou). La situation typique est l’appariement entre deux sources de données selon un identifiant individuel ou un identifiant de code commune, ce qui est notre cas.
Il est recommandé de lire ce guide assez complet sur la question des jointures avec R qui donne des recommandations également utiles en python.
On utilise de manière indifférente les termes merge ou join. Le deuxième terme provient de la syntaxe SQL. En pandas, dans la plupart des cas, on peut utiliser indifféremment df.join et df.merge

Reshape
On présente généralement deux types de données:
* format __wide__: les données comportent des observations répétées, pour un même individu (ou groupe), dans des colonnes différentes
* format __long__: les données comportent des observations répétées, pour un même individu, dans des lignes différentes avec une colonne permettant de distinguer les niveaux d'observations
Un exemple de la distinction entre les deux peut être pris à l’ouvrage de référence d’Hadley Wickham, R for Data Science:

L’aide mémoire suivante aidera à se rappeler les fonctions à appliquer si besoin:

Le fait de passer d’un format wide au format long (ou vice-versa) peut être extrêmement pratique car certaines fonctions sont plus adéquates sur une forme de données ou sur l’autre. En règle générale, avec python comme avec R, les formats long sont souvent préférables.
Le TP pandas
![]()
![]() propose une série d’exemples sur la manière de restructurer les données en
propose une série d’exemples sur la manière de restructurer les données en
pandas.
Quelques enjeux de performance
Ouverture sur dask?
Références
- Le site pandas.pydata fait office de référence
…
-
En
R, les deux formes de dataframes qui se sont imposées récemment sont lestibbles(packagedplyr) et lesdata.tables(packagedata.table).dplyrreprend la syntaxe SQL de manière relativement transparente ce qui rend la syntaxe très proche de celle depandas. Cependant, alors quedplyrsupporte très mal les données dont la volumétrie dépasse 1Go,pandass’en accomode bien. Les performances depandassont plus proches de celles dedata.table, qui est connu pour être une approche efficace avec des données de taille importante. ↩︎